
How to reduce Redux boilerplate?
State management might get difficult. Business logic is complex and the tools we use can, and will, fight back occasionally. Business logic requires writing hundreds of lines of code to make it actually work. In some cases, most of it may be a boilerplate we don’t necessarily have to write.
The goal of this blog post is to help you comprehend and solve the problem of having excessive amounts of written code while implementing Redux components such as reducers and actions, and also to show you the right way to migrate for a better solution.
State management problem
Managing state in frontend applications is considered a difficult task. There are many factors that may add up to the overall complexity of the problem. The more robust solution you build, and the more complex features it covers. It will require better organization and extreme care in the architecture design process. You will notice a rapid growth of your project’s codebase, especially during feature creep.
What happens when you don’t have enough time for proper maintenance? Or if refactoring and/or requirements are changing? You will likely lean towards using some workaround solutions – this is not ideal, even if you use the best you can with substantial resources available at that given time. As the complexity of your code increases, logic becomes more convoluted and your components get more and more coupled.
To make things worse, tools do not help. Instead of simply solving the problem, it is critical to handle repetitive issues that correspond to the technology used, e.g. introducing changes by deeply, or partially, copying objects in JavaScript due to the reference identity comparison. It is a matter of accidental complexity that makes it hard for us developers to do our job – we stop focusing on the real domain problems and struggle with issues dictated by the software we write.
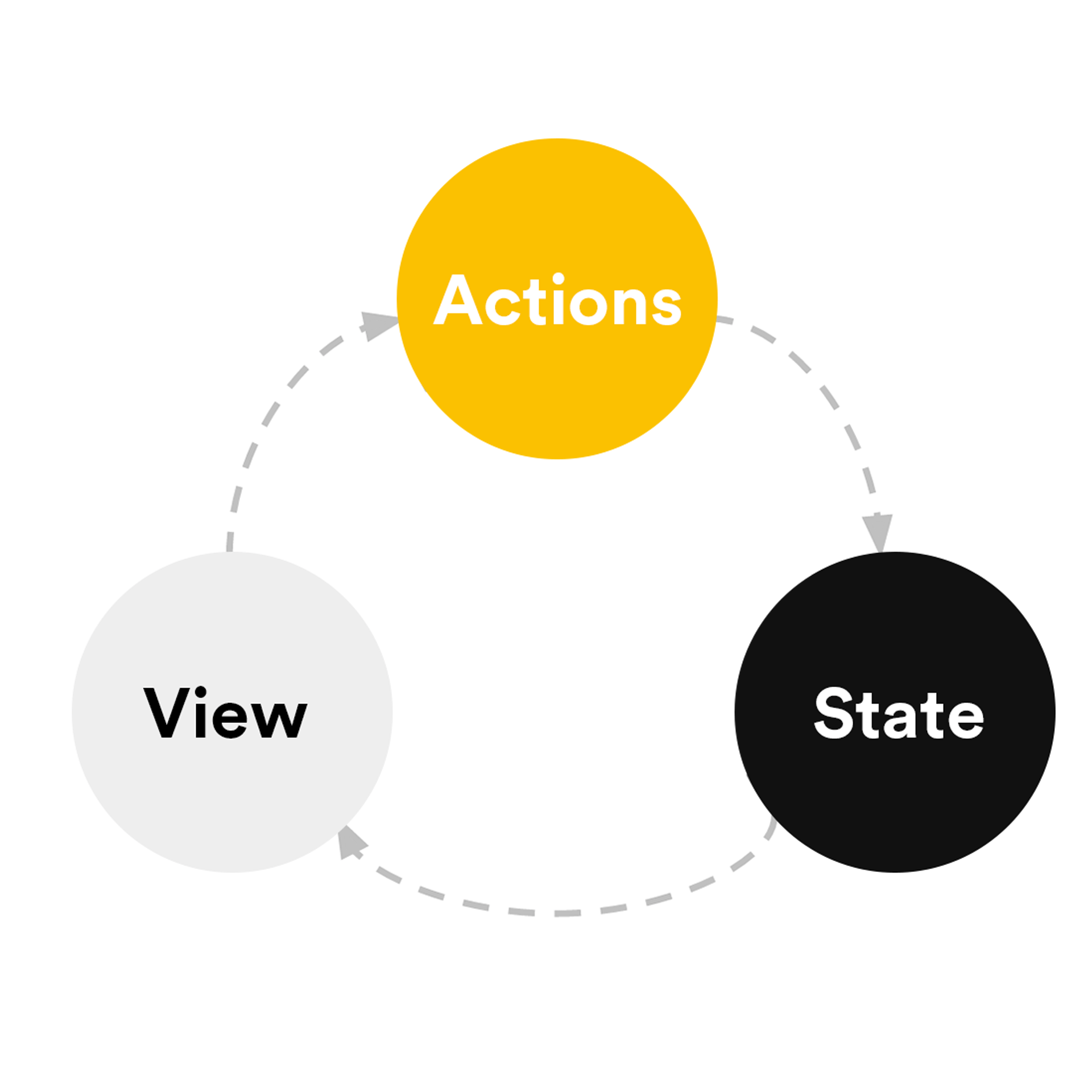
Let’s talk about Redux
What does it mean when it says that Redux is a state container for JavaScript applications? It means that Redux allows storing state values and determines how these values are being accessed and modified. It helps to get over a number of challenges in component-based libraries like React. The most obvious one is the sharing state between several components. If we go the React way, then the solution is to lift the state up. By doing this, we’ll possibly end up with the state stored somewhere at the very top of the component tree, which will create another problem — props drilling. In some cases, this could be solved by the appropriate composition of components leveraging children or render props.
For others, it may be convenient to take state logic out of the component and just store it separately, which Redux does. By these means, we are able to access state in different parts of the application without much overhead. At this point, we are talking about logic that could be implemented fairly easily with React Context API. This would require extra caution when dealing with high-frequency re-renders, but it’s still doable. However, we’re not stopping there. Redux implements Flux architecture which simplifies data flow in the application by making it unidirectional with the use of simple action objects and reducer functions, and it also adds support for hot reloading them.
Unfortunately, although Redux already makes implementing stores more straightforward, its original purpose wasn’t about reducing syntax boilerplate along the language specific mechanisms. With some experience gathered over a couple of years of Redux existence, it is easier to draw accurate conclusions and choose better, already existing solutions for recurring problems. Happily, for newer codebases, it is more likely that you will see more refined approaches being used, but there are still some legacy projects which tend to cause unnecessary pain for no particular reason!
Old school
The Redux library was initially released in 2015 and the way it’s used by developers has evolved throughout the years due to developers’ experience. One of the main reasons for creating Redux was to remove the conceptual boilerplate from Flux, but removing the actual syntax boilerplate wasn’t necessarily part of that goal.
Let’s take an example. A simple To-Do list with a visibility filter.
So, we have a bunch of keys for some basic actions:
// constants.js
// ...
export const ADD = 'todoList/add';
export const REMOVE = 'todoList/remove';
export const COMPLETE = 'todoList/complete';
export const SET_VISIBILITY = 'todoList/setVisibility';Now, let’s create corresponding action creators, which will make the code a little bit tighter right away:
// actionCreators.js
// ...
export const add = name => ({
type: ADD,
payload: name,
});
export const remove = byIndex => ({
type: REMOVE,
payload: byIndex,
});
export const complete = byIndex => ({
type: COMPLETE,
payload: byIndex,
});
export const setVisibility = state => ({
type: SET_VISIBILITY,
payload: state,
});That’s quite a lot of code already, but we haven’t added a reducer yet. Let’s start with a simple initial state:
// reducer.js
// ...
const initialState = {
visibility: Visibility.All,
tasks: [{
name: 'Reduce Redux Boilerplate',
isCompleted: false,
}],
};
// ...We have an array for tasks and some visibility status for filtering. It’s time for the reducer function:
// reducer.js
// ...
export function reducer(state = initialState, action) {
switch (action.type) {
case ADD:
return {
...state,
tasks: [
...state.tasks,
{
name: action.payload,
isCompleted: false,
},
],
};
case REMOVE:
return {
...state,
tasks: state.tasks.filter(
(_, index) => index !== action.payload,
),
};
case COMPLETE:
return {
...state,
tasks: state.tasks.map(
(task, index) => index === action.payload
? { ...task, isCompleted: true }
: task,
)
}
case SET_VISIBILITY:
return {
...state,
visibility: action.payload,
};
default:
return state;
}
}Despite serving only four actions, it already looks bloated. If we think about the main purpose of this reducer, we may come to the conclusion that it should respond to the following four actions and alter its state respectively: adding, removing, marking as complete and changing the visibility filter. There’s no magic here, we shouldn’t care about the low-level ins and outs, it’s not necessary. Instead, we are obligated to take care of control flow using switch statements, handle default cases, and manage change detection by instantiating new objects through spread operators. This is especially painful when it’s dealt with on the nested levels.
Let’s take a closer look at the add action reducer logic:
case ADD:
return {
...state,
tasks: [
...state.tasks,
{
name: action.payload,
isCompleted: false,
},
],
};Instead of appending a new task to the array, not only do we have to copy the array, but also the whole state. We also need to write this logic almost every time and for every action. In addition, the logic is spread over three files. We actually need to traverse all of them whenever we need to make changes like adding a new action or changing another’s action name. For a small app with not many reducers like the one above, it shouldn’t be too much of a problem, but as the application grows, it may become more and more overwhelming. It’s worth noting that code written in such a manner takes up more and more space, especially for repeated logic related to object copying.
So, why do I actually call it boilerplate? Because all these side-issues don’t implement real business logic. You don’t need them to express what needs to be done, or at least you need them only at some bonding level which isn’t necessary to worry about on a daily basis. That’s just redundancy, which may originate from the tool being used or the way it is used.
Does it have to repeat?
If you have to repeat a very tedious task over and over again, then the ideal solution is to automate it, ideally through helpers and add some layer of abstraction which would do all the nasty bits for you. In actual fact, there is a page in the Redux documentation about handling code’s verbosity — helper functions to the rescue!
So let’s try to clean it up a little bit. Imagine we could use an object for defining our reducers:
{
action: reducer,
anotherAction: anotherReducer,
...
}Instead of writing a lot of code for switch statements, which are just picking blocks of instructions based on some primitive value, we could just access them in a more concise way.
{
add: (state, name) => ({
...state,
tasks: [
...state.tasks,
{
name,
isCompleted: false,
},
],
}),
remove: (state, byIndex) => ({
...state,
tasks: state.tasks.filter((_, index) => index !== byIndex),
}),
complete: (state, byIndex) => ({
...state,
tasks: state.tasks.map(
(task, index) => index === byIndex
? { ...task, isCompleted: true }
: task,
)
}),
setVisibility: (state, value) => ({
...state,
visibility: value,
}),
};Code that will generate the final reducer:
// helpers.js
export function createReducer(name, config, initialState) {
return (state = initialState, action) => {
const type = action.type.replace(new RegExp(`^${name}/`), '')
return config[type]?.(state, action.payload) ?? state
};
}
// ...What’s even more interesting is that we can use the same config object to generate action creators using such function:
// helpers.js
// ...
export function createActions(name, config) {
return Object.keys(config).reduce((prevActions, key) => {
prevActions[key] = (payload = {}) => ({
type: `${name}/${key}`,
payload
})
return prevActions
}, {});
}When we combine it all together:
// slice.js
// ...
const name = 'todoList';
const initialState = {
visibility: Visibility.All,
tasks: [{
name: 'Reduce Redux Boilerplate',
isCompleted: false,
}],
};
const reducerConfig = {
// the aforementioned config...
};
export const reducer = createReducer(name, reducerConfig, initialState);
export const actions = createActions(name, reducerConfig);The code is already simpler. We no longer need to write control flow instructions for selecting the right reducer. Also, we have eliminated the action key constants as they are no longer needed. Additionally, the actual reducer logic is contained in a single file. The reducer and its actions are doing the same job as in the original example.
The boilerplate is still related to the immutability of state, however. There are a couple of solutions for this problem. If you seek knowledge on them or want to know the differences, I recommend reading this article. We could break this problem down further and try to implement one of them, but…
…there is a library for that…
…and it is an official approach promoted by the Redux team – Redux Toolkit.
It introduces several utility functions to simplify Redux usage as well as introducing the concept of “slices”. The whole idea is to write reducers for a portion of state and get action creators and action types generated automatically. Of course, it was designed for specific usages, but it turns out that it has quite a wide array of applications. We have used it in our projects for over a year now and we can really see the difference – it’s been a real pleasure to use.
Let’s get back to code. Here is the migrated solution:
// slice.js
// ...
export const { actions, reducer } = createSlice({
name: 'todoList',
initialState: {
visibility: Visibility.All,
tasks: [{
name: 'Reduce Redux Boilerplate',
isCompleted: false,
}],
},
reducers: {
add: (state, { payload: name }) => {
state.tasks.push({
name,
isCompleted: false,
});
},
remove: (state, { payload: byIndex }) => {
state.tasks.splice(byIndex, 1);
},
complete: (state, { payload: byIndex }) => {
state.tasks[byIndex].isCompleted = true;
},
setVisibility: (state, { payload: value }) => {
state.visibility = value;
},
},
});As we can see, the initial state, name and reducers were contained inside the createSlice function call. There are also some very significant changes, one being that Reducer logic was simplified greatly. This was due to the usage of the Immer library, which allows us to manage the immutable state in a mutable manner. Therefore, instead of going to the trouble of cloning objects and arrays, we can just update the desired part of the state and when reducer logic finishes, it will create a new copy of state with all the changes applied. We don’t have to worry about that anymore and so we can focus on actual state modifications.
Let’s look at the add reducer logic again:
add: (state, { payload: name }) => {
state.tasks.push({
name,
isCompleted: false,
});
},It is very concise now. We no longer play with spread operators, but just use fluent API to push the object into the array. This works like a charm thanks to JavaScript proxies used by Immer.
Sometimes we want to update the state as a result of external action. Is this possible? Yes, it is. We can use extraReducers for that:
extraReducers: {
'external/action': state => {
state.tasks = [];
},
},Whenever we dispatch “external/action” it will invoke the corresponding logic.
The Redux Toolkit also provides some other utilities and comes with support for TypeScript. Although it may not fit every case, for example more complex action routing scenarios, it is still very generic. It only returns the typical reducers and actions, so you can even use it for many of your reducers and implement others using a different approach. Overall, this library adds greatly to code quality, readability and maintainability. It abstracts much of the boilerplate away and lets you focus on delivering value.
Three main concerns I’ve come across
Sometimes we get used to some approach and changing it may not sound very appealing. There may be many reasons why this is so, but it’s always good to think about them and evaluate the potential gain the change may bring. Rethinking the way we write Redux code may reduce the amount of boilerplate we create and increase efficiency overall, but there are still some concerns I’ve heard that make people refrain from making the change.
#1 “It’s magic, I don’t understand how it works”
In my opinion, this statement applies to many different areas of software engineering. They are complex and you have to put some effort into understanding them. You probably use many different libraries, some simpler, some more complex. It’s often about abstraction or inverse of control, you reach out for a tool to simplify your job because we don’t want to write something that is already available. It’s also about trust. How do you know the library you’ve picked is reliable? You probably either try to check how it is built, or you base this judgment on its popularity and usage metrics. Sometimes you have to give it a try and do some research, that’s how we learn and make our work simpler.
In this scenario, the most probable thing that may look magical is the state mutation. We all know that for efficiency the state values are compared by reference, so we need to deep copy updated state. This is the role of the Immer library here. It handles immutability by abstracting copy-on-write logic.
#2 “It is slow”
Redux Toolkit uses Immer under-the-hood so there is some influence, but have you measured how it really impacts your case? You can always mix the approaches, implement general reducers using Redux Toolkit or some other toolset, and any other critical approaches in a raw way. Don’t hesitate to use something just because it adds some insignificant overhead, especially when it can bring much more value. Test it out.
#3 “It wouldn’t be consistent with the rest of my app”
Consistency is important, but only if we compare similar solutions. If there is a better one that is worth the effort then it’s obvious that you should migrate. Particularly when the change can be incremental, e.g. one reducer after another. Maybe for a legacy project with a huge codebase though it wouldn’t make much sense until it is actively developed.
Summary
We went through the problem of boilerplate code written while using Redux. It seems feasible to clean it up if you aren’t already using an approach like the one guided by Redux Toolkit. I’ve used this library for a couple of projects already and I highly recommend it. It is strongly recommended by the Redux team as well.
It’s always good to think about the tools we are using and re-evaluate them on a regular basis. The world is moving forwards and new improvements are developed every day almost. We need to be able to evolve, to change, and adapt. It’s not always easy, sometimes it may not make sense and we should stop and think for a moment. We shouldn’t ever be subordinate to the developer tools we use, we just need to make them work for us.
If you want to check out the full code go to the GitHub repository.